Kafka集群设计原理
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
Kafka并没有遵循JMS规范,它只提供了发布和订阅通讯方式。
kafka中文官网:http://kafka.apachecn.org/quickstart.html
一、Kafka核心相关名称
Broker:kafka节点,一个kafka就是一个broker,多个可以可组成一个集群
Topic:主题,相当于一个一类消息,kafka集群能够同时负责多个topic的分发
message:消息
Partition:topic上一个物理分区,一个topic可以有多个Partition,每个Partition是一个有序的队列
Segment:Partition是由多个Partition组成,每个Segment存放着独立的message
Producer:生产者,推送消息到topic中
Consumer:消费者,订阅topic并消费message,Consumer作为一个线程来消费
Offset:偏移量,相当于消息Partition中的索引即可
二、Kafka集群环境搭建
1.每台服务器上安装jdk1.8环境
2.安装Zookeeper集群环境(本文使用三台服务器集群)
3.安装kafka集群环境(本文使用三台服务器集群)
4.运行环境测试
##服务器ip如下 192.168.75.130 192.168.75.132 192.168.75.133本文使用Kafka2.11版本,需要依赖Zookeeper,最新版本的Kafka无需搭建Zk
1.Zookeeper集群环境搭建
> tar -zxvf zookeeper-3.4.14.tar.gz
> cd zookeeper-3.4.14
> mv zoo_sample.cfg zoo.cfg
> vi zoo.cfg
## 修改zoo.cfg两处 三台服务器一样
## 1.修改dataDIr路径,并创建data目录
dataDir=/usr/local/zookeeper-3.4.14/data
## 2.添加
server.0=192.168.75.130:2888:3888
server.1=192.168.75.132:2888:3888
server.2=192.168.75.133:2888:3888
## 分别在三台zookeeper服务器创建myid文件,添加唯一标识id
> cd /usr/local/zookeeper-3.4.14/data
> touch myid
> vi myid
1
## 其余两台分别为1、2
# 启动Zookeeper 三台同时执行
> cd /usr/local/zookeeper-3.4.14/bin
> ./zkServer.sh start
# 查看zk状态
> zkServer.sh status
# 出现Mode:follower或是Mode:leader则代表成功2.Kafka集群环境搭建
> tar -zxvf kafka_2.11-2.2.1.tgz
> vi ./kafka_2.11-2.2.1/config/server.properties
## 分别修改3处
### 1.kafka唯一标识
broker.id=0
### 2.申明此kafka服务器需要监听的端口号
listeners=PLAINTEXT://192.168.75.130:9092
### 3.zk集群ip
zookeeper.connect=192.168.75.130:2181,192.168.75.132:2181,192.168.75.133:2181
## 其余两台只需修改broker.id,分别为1、2即可
# 后台启动kafka集群
> cd /usr/local/kafka_2.11-2.2.1/bin
> ./kafka-server-start.sh -daemon ../config/server.properties
## 在其中一台服务中创建topic主题
> ./kafka-topics.sh --create –zookeeper 192.168.75.130:2181 –replication-factor 3 –partitions 1 –topic my-replicated-topic
## 查看创建的topic信息
> kafka-topics.sh –describe –zookeeper 192.168.75.130:2181 –topic my-replicated-topic详情文档参考官网 http://kafka.apachecn.org/quickstart.html
三、Kafka保证消息顺序性
Kafka集群是如何知道投递到那个broker中呢?靠的就是生产者在投递消息的时候传递key,根据key计算hash值存在到具体的broker中,如果是相同的key,最终投递消息都是同一个broker中。
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "mayikt", partitions = {"0"})})
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
}场景:比如我们基于MQ解决Redis与MySql数据一致性的问题,可以采用MQ订阅MySQL binLog文件异步的实现数据的同步;先发送insert、update、delete的请求到同一个的队列中存放。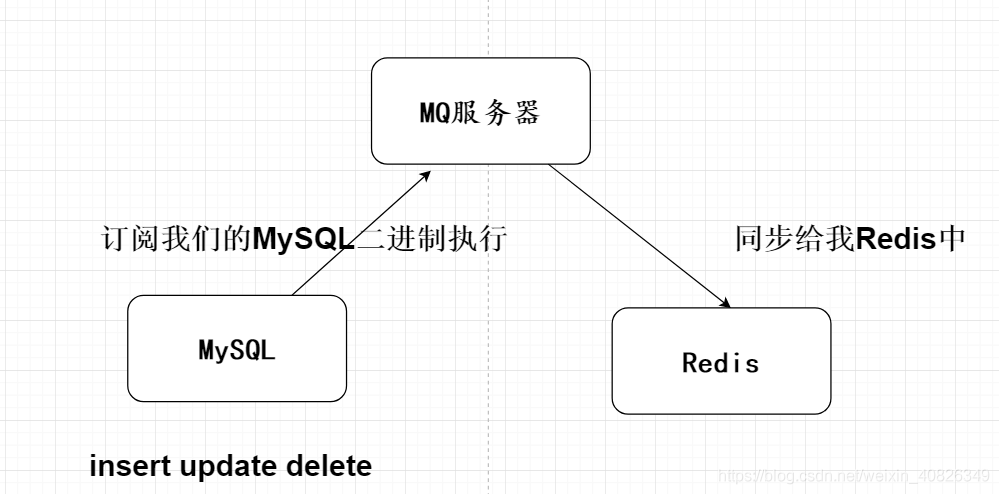
四、RabbitMQ如何保证消息顺序性问题
Kafka默认只要设置是相同的key最终都会存放到同一个分区中,每个分区中单独对应一个消费者实现消费。
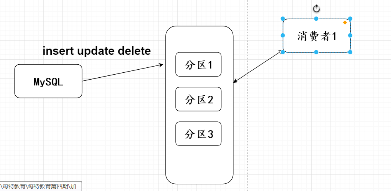
但是如果消费者中里面是多线程的时候,这时候也会存在顺序的问题,采用内存队列形式实现,每个内存队列对应Thread线程从而提高速率。
四、Kafka如何保证高吞吐量
- 使用顺序写方式实现数据存储
Kafka是采用不断的将数据追加到文件中,该特性利用了磁盘的顺序读写性能比传统的磁盘读写可以减少寻地址浪费的时间;
- 能够支持生产者与消费者(批量发送和批量消费) 减少ioc操作
可以将消息投递到缓存区中,在以定时或者/缓存大小方式将数据写入到MQ服务器中,
这样可以减少IO的网络操作,但是这种方式也存在很大缺陷数据可能会丢失。
数据零拷贝
实现数据的分区
根据Partition实现对我们的数据的分区
- 数据的压缩 会对我们的数据实现压缩,减少网络的传输
``
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!